Part 1 第一次作业
第一次作业
考虑到整个作业可以被分为两个部分:建立计算关系+用某种结构承载计算结果
为了方便化简,用于承载计算结构的结构必须有统一的形式
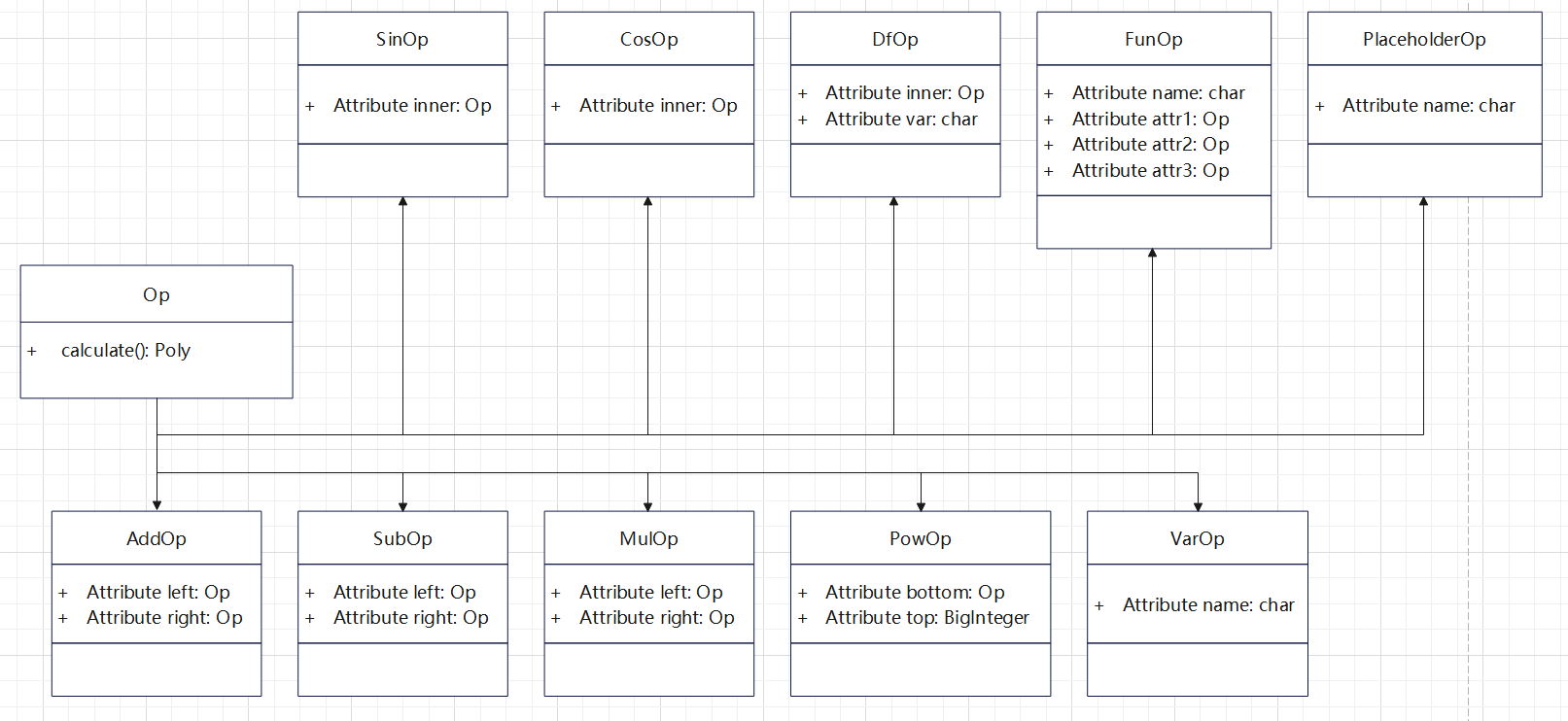
计算关系的构建采用传统的表达式树,树上的每个节点被抽象成一个Op,每当新增一种计算类型时,考虑通过拓展Op的种类来将新计算嵌入表达式树;以下是截至到第三次作业,我所拓展出来的关于Op的类图:
接下来考虑如何统一计算结果的结构
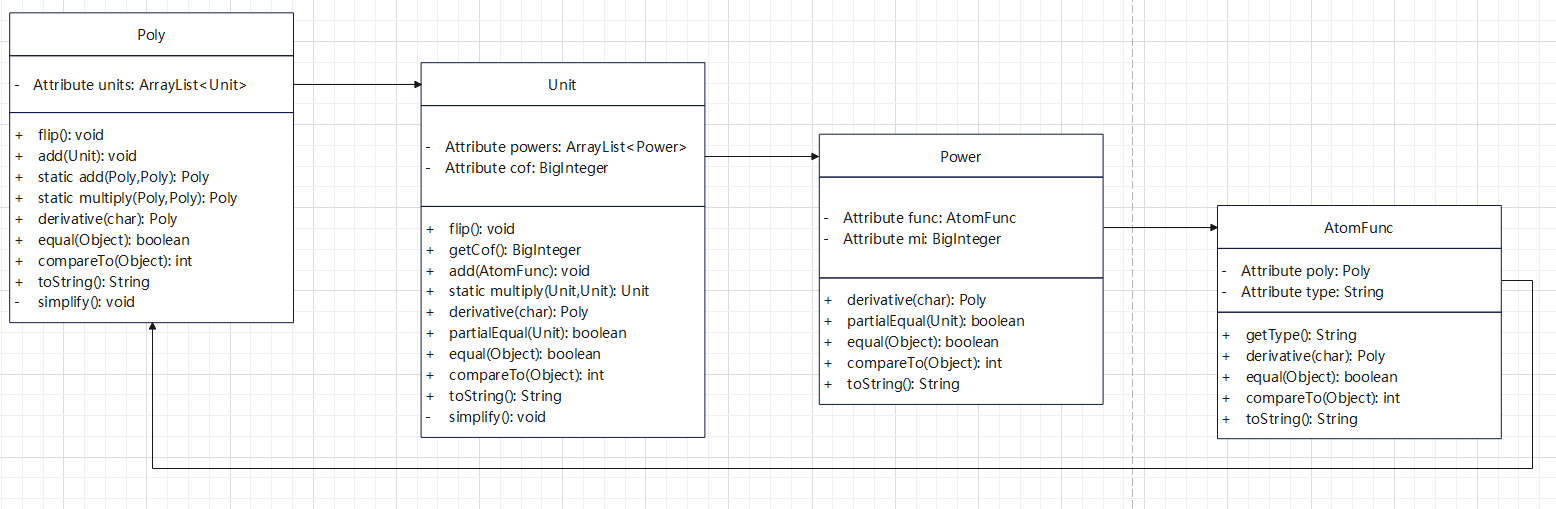
可以发现最后计算结果一定会形如:\(x^2y^3+xcos(?)-z^3sin^2(?)\)
可以粗略将其分成四层:
- 用加减号连接的
Poly - 用乘号连接的
Unit - 持有一个底数和一个指数的
Power - 基本函数,
x|y|z|cos|sin,基础函数内部可能持有Poly
我最后的设计如下:
在解析字符串的过程中,我认为首先对字符串预处理,将其转化成为Token序列,再将Token序列喂给Parser会是一个比较方便的实现方式;在Parser中采用递归下降,生成一个表达式树
我个人觉得instanceof简直是设计失败的补救,所以本次作业在代码避免出现任何一处instanceof
Part 2 第二次作业
添加了自定义函数
考虑到普通程序里面的函数调用,我们会用一个栈来保存参数列表,那么在本次作业中我也进行了类似的设计:

FunDefine里面包含了一棵表达式树,表示这个函数的定义
FunOp作为表达式树上的节点,当对其进行计算时,它会使用FunEnv来告诉全局,现在进入了某个函数内部进行计算,同时将参数入栈;FunEnv的计算过程就是调用FunDefine内部的表达式树的计算的过程;在FunDefine内部的PlaceholderOp中,会通过查询FunEnv的参数栈来获取该占位符的具体值
Part 3 第三次作业
对“承载计算结果”的数据结构,即Poly,Unit,Power,AtomFunc都定义好对应的求导函数即可
代码分析
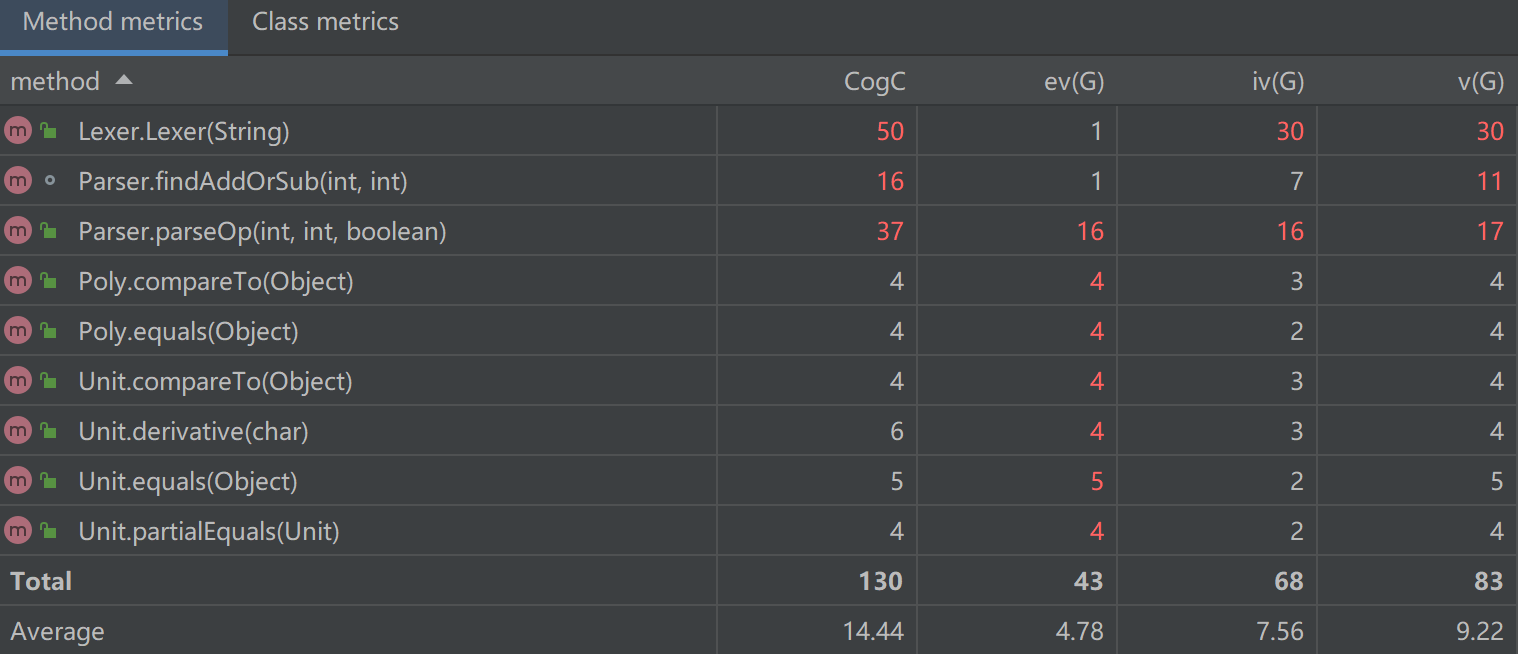
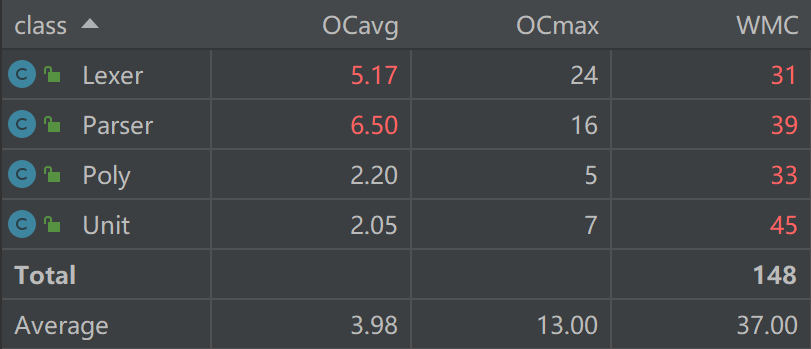
可以发现Lexer和Parser中的方法的认知复杂度较高,因为我采用的是一个类有一个大方法进行解析的操作,其内有较多的分支判断,打破了代码的连续性