A3C
全称异步优势动作评价算法(Asynchronous Advantage Actor-Critic)
在神经网络训练的时候,需要的数据是独立同分布的,为了打破数据之间的相关性,DQN和DDPG等都用到了Replay Buffer,然而经验回放需要大量的内存。打破数据的相关性还有别的方法,另外一种是异步的方法,即,数据并非同时产生
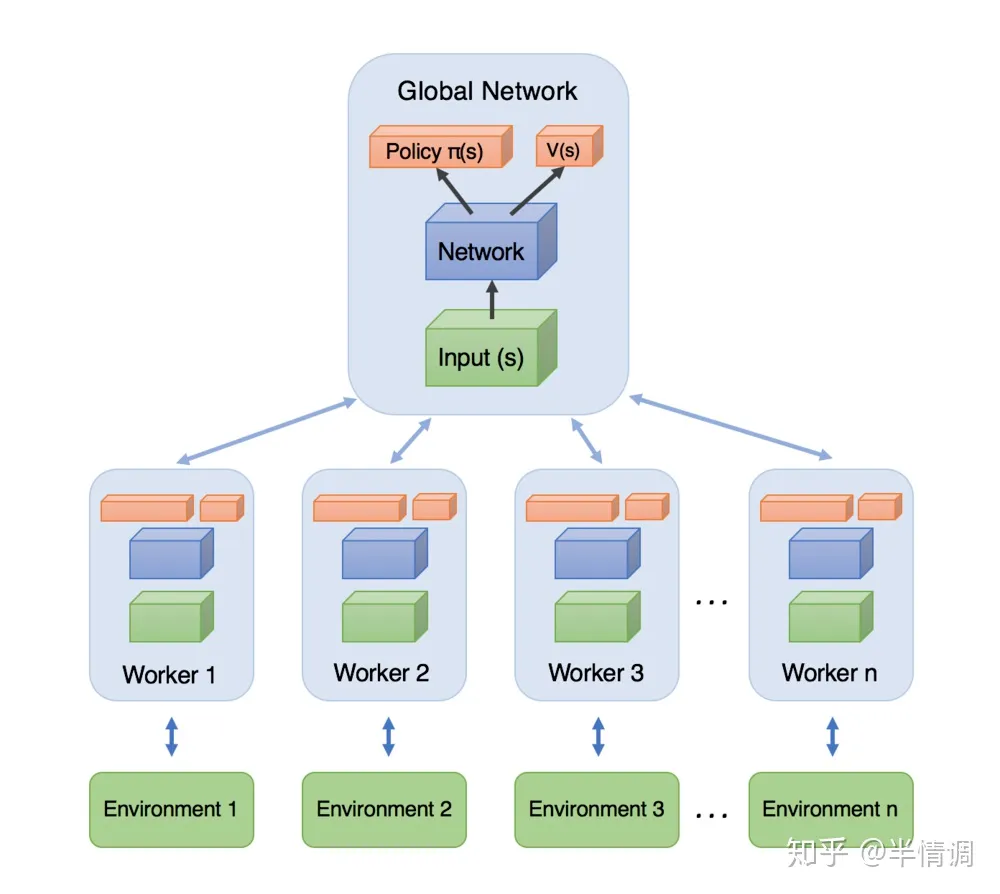
A3C模型如上,每一个Worker直接从Global Network里面拿参数,自己和环境互动输出行为,利用每个Worker的梯度,对Global Network的参数进行更新,每一个Worker都是一个A2C