进程=内核数据结构(PCB)+该程序的代码+数据集合
PCB
进程控制块,Process Ctrl Block,是操作系统为了管理进程设置的一个专门的结构体task_struct,操作系统用它来记录进程的外部特征,描述进程的运动变化过程,控制和管理进程
task_struct
pid:每个进程唯一标识符。pid为0的进程为调度进程,该进程是内核的一部分;pid为1的进程为init进程,它是一个普通的用户进程,但是以超级用户特权运行;pid为2的进程是页守护进程,负责支持虚拟存储系统的分页操作
#include<unistd.h>
pid_t getpid(void); // 获取该进程的pid
pid_t getppid(void); // 获取该进程的父进程pid
uid_t getuid(void); // 获取调用该进程的实际用户id
uid_t geteuid(void); // 获取调用该进程的有效用户id
gid_t getgid(void); // 获取调用该进程的实际组id
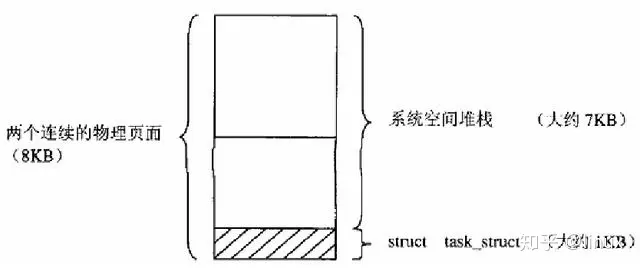
git_t getegid(void); // 获取调用该进程的有效组id每个进程都有两个栈:用户空间栈和内核栈(系统空间栈),task_struct和系统空间栈存放位置如下(两个连续的物理页):
进程创建
Linux系统创建进程都是由已存在的进程创建的(除了0号进程),被创建的进程叫做子进程,创建子进程的进程就做父进程
0/1/2号进程
- 0号进程:在内核初始化的过程中,会先通过
struct task_struct init_task=INIT_TASK(init_task)创建0号进程,这是唯一一个不通过fork或者kernel_thread产生的进程,是进程列表的第一个 - 1号进程:通过调用指令
kernel_thread(kernel_init,NULL,CLONE_FS)从内核态切换到用户态来创建的,1号进程是所有用户态的祖先 - 2号进程:通过调用指令
kernel_thread(kthreadd,NULL,CLONE_FS|CLONE_FILES)来创建,2号进程负责所有内核态的进程的调度和管理,是内核态所有进程的祖先(注意,内核态不分线程和进程,都是任务)
为什么先创建0号进程,而不直接创建1号进程
简单来说就是Linux 的第一个进程不适合是一个真进程,需要一个没有数据之类东西的假进程
为什么要区分用户态和内核态
因为有了多个进程,对于关键资源来说,就会产生争用以及误操作破坏资源等情况。这时就需要对资源的访问权限进行一定的限制。x86提供了分层的权限机制,内核态具有最高的访问权限,而用户态访问核心资源时必须要切换到内核态才可以访问
fork
fork是类Unix操作系统上创建进程的主要方法,fork用于创建子进程,采用COW技术避免创建进程时大量拷贝,父子进程的执行次序不确定
vfork
起源:因为以前的fork当它创建一个子进程时,将会创建一个新的地址空间,并且拷贝父进程的资源,而往往在子进程中会执行exec调用,这样,前面的拷贝工作就是白费力气了,这种情况下,聪明的人就想出了vfork,它产生的子进程刚开始暂时与父进程共享地址空间(其实就是线程的概念了),因为这时候子进程在父进程的地址空间中运行,所以子进程不能进行写操作。并且当子进程占用着父进程的空间时,父进程不许执行,一旦子进程执行完exec或者exit后,子进程有了自己的空间,父进程才可能被调度运行
exec函数族
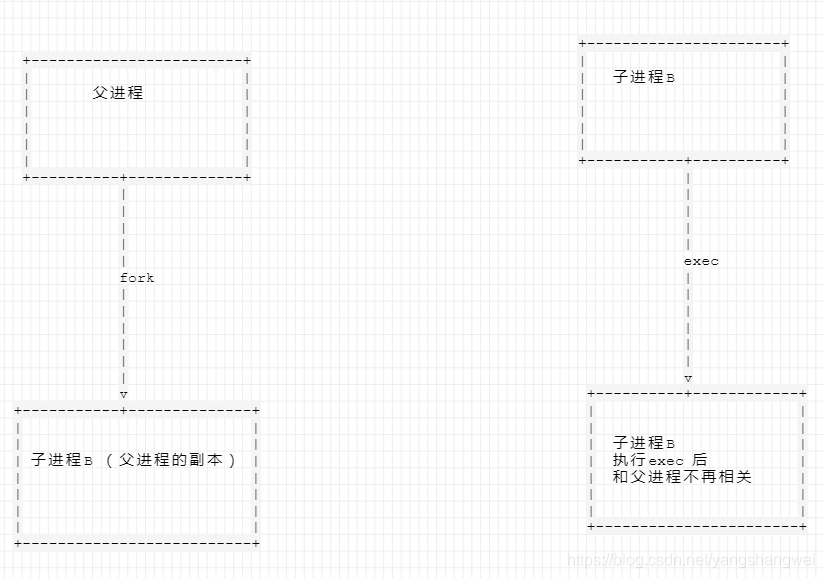
在Linux中使用exec函数族,系统调用execve()对当前进程进行替换,替换成一个指定程序,其参数包括文件名,参数列表以及环境变量
一旦一个进程调用exec类函数,它本身就死亡了,系统把代码段替换成新的程序的代码,废弃原有的数据段和堆栈段,并为新程序分配新的数据段和堆栈段,唯一留下的就是进程号
Copy-on-Write,COW
fork创建出的子进程,与父进程共享内存空间。 如果子进程不对内存空间进行写入操作的话,内存空间中的数据并不会复制给子进程,这样创建子进程的速度就很快 ,因为不用复制,直接引用父进程的物理空间 ,并且如果在fork函数返回之后,子进程第一时间exec一个新的可执行映像,那么也不会浪费时间和内存空间了
fork之后,kernel把父进程中所有的内存页的权限都设为read-only,然后子进程的地址空间指向父进程。当父子进程都只读内存时,相安无事。当其中某个进程写内存时,CPU硬件检测到内存页是read-only的,于是触发页异常中断(page-fault),陷入kernel的一个中断例程。中断例程中,kernel就会把触发的异常的页复制一份,于是父子进程各自持有独立的一份