在开始前
- 一个多CPU的系统中,每个CPU的频率是不一定同步的
MESI
| 状态 | 图例 | 解释 |
|---|---|---|
| M | 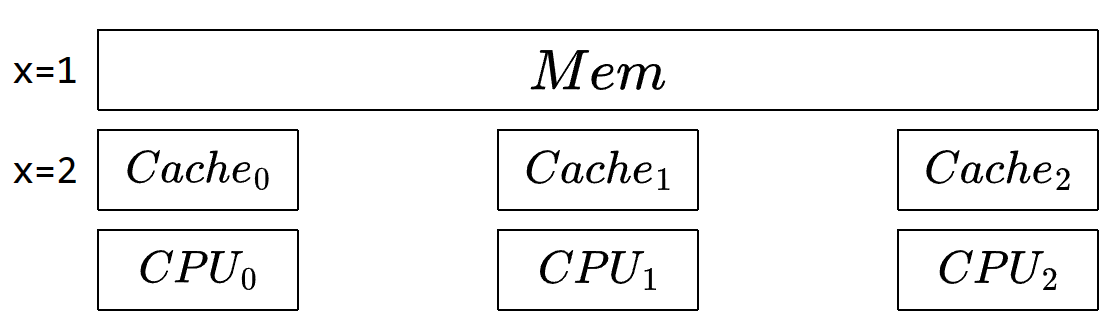 |
只在当前Cache 被修改过 |
| E |  |
只在当前Cache 没修改过 |
| S |  |
在多个Cache 没修改过 |
| I | 缓存已失效 | 其他情况 |
总线嗅探机制:CPU感知其他CPU的行为,是通过嗅探总线中其他CPU发出的请求消息完成的,有时CPU也需要针对总线中的某些消息进行响应
| 消息 | 请求/响应 | 描述 |
|---|---|---|
| Read | 请求 | 通知其他处理器和内存,当前处理器准备读取某个数据。该消息包含待读取数据的内存地址 |
| Read Response | 响应 | 该消息包含了被请求读取的数据。该消息可能是内存返回的,也可能是其他高速缓存嗅探到Read消息返回的 |
| Invalidate | 请求 | 通知其他处理器删除指定内存地址的数据副本 |
| Invalidate Acknowledge | 响应 | 接收到Invalidate消息的处理器必须回复此消息,表示已经删除了其高速缓存内对应的数据副本 |
| Read Invalidate | 请求 | 请求一份数据,并且顺便把该数据在别的高速缓存处给Invalidate了。收到该消息的处理器应返回一个Read Response和一个Invalidate Acknowledge |
| Writeback | 响应 | 把数据写回内存 |
分类讨论
为了分类讨论更加直观,我们把一个缓存行想象成一个变量\(x\)
\(M\rightarrow E\)
- 描述:从独占一个和内存不一致的变量\(x\),到独占一个和内存一致的变量\(x\)
- 流程:
- 发出一个Writeback响应,把\(x\)写回内存
- 于是,缓存中\(x\)与内存中\(x\)一致了
- 触发时机:不知道
\(E\rightarrow M\)
- 描述:从独占一个和内存一致的变量\(x\),到独占一个和内存不一致的变量\(x\)
- 流程:
- CPU自己改了缓存中的\(x\)
- 于是,缓存中\(x\)与内存中\(x\)不一致了
- 触发时机:本地写
\(M\rightarrow I\)
- 描述:从独占一个和内存不一致的变量\(x\),到变量\(x\)失效
- 流程:
- 收到一个Read Invalidate请求
- 发出一个Read Response,携带\(x\)的值
- 将\(x\)失效
- 发出一个Invalidate Acknowledge
- 触发时机:别的CPU想要进行原子read-modify-write操作
\(I\rightarrow M\)
- 描述:从变量\(x\)失效,到独占一个和内存不一致的变量\(x\)
- 流程:
- 发出一个Read Invalidate请求
- 收到一个Read Response,包含了\(x\)的值
- 收到很多Invalidate Acknowledge,所有响应都收到后,修改\(x\),转为\(M\)
- 触发时机:当前CPU想要进行read-modify-write操作
\(S\rightarrow M\)
- 描述:从共享变量\(x\),到当前CPU独占一个和内存不一致的变量\(x\)
- 流程:
- 发出一个Invalidate请求
- 收到很多Invalidate Acknowledge,所有响应都收到后,修改\(x\),转为\(M\)
- 触发时机:当前CPU想要进行read-modify-write操作
\(M\rightarrow S\)
- 描述:从独占一个和内存不一致的变量\(x\),到共享变量\(x\)
- 流程:
- 收到一个Read请求
- 返回一个Read Response,携带了\(x\)
- 触发时机:别的某个CPU可能想要读取\(x\)的值
\(E\rightarrow S\)
- 描述:从独占一个和内存一致的变量\(x\),到共享变量\(x\)
- 流程:
- 收到一个Read请求
- 返回一个Read Response,携带\(x\)的值
- 触发时机:别的某个CPU可能想要读取\(x\)的值,这个值既可以从内存提供,也可以从当前CPU提供
\(S\rightarrow E\)
- 描述:从共享变量\(x\),到独占一个和内存一致的变量\(x\)
- 流程:
- 发出一个Invalidate请求
- 收到很多Invalidate Acknowledge,所有响应都收到后,转为\(E\)
- 或者,别的CPU在丢弃这个变量\(x\)(缓存不够用了),这个CPU是最后一个拥有\(x\)的
- 触发时机:预测到当前CPU很快就要往变量\(x\)中写入了,这其实是一个中间状态,最终的目的还是转为\(M\),即可以参考\(S\rightarrow M\)
\(E\rightarrow I\)
- 描述:从独占一个和内存一致的变量\(x\),到变量\(x\)失效
- 流程:
- 收到一个Read Invalidate请求
- 发出一个Read Response,携带\(x\)的值
- 发出一个Invalidate Acknowledge
- 触发时机:别的CPU想要进行read-modify-write操作
\(I\rightarrow E\)
- 描述:从变量\(x\)失效,到独占一个和内存一致的变量\(x\)
- 流程:
- 发出一个Read Invalidate请求
- 收到一个Read Response,包含了\(x\)的值
- 收到很多Invalidate Acknowledge,所有响应都收到后,转为\(E\)
- 触发时机:\(I\rightarrow E\)大概率不是一个最终状态,CPU实际目的还是希望能修改\(x\)的值,所以一旦实际存储完成,缓存行可能会经历\(E\rightarrow M\),或者连在一起看,就是\(I\rightarrow M\)
\(I\rightarrow S\)
- 描述:从变量\(x\)失效,到共享变量\(x\)
- 流程:
- 发出一个Read请求
- 收到一个Read Response,包含了\(x\)的值
- 触发时机:该CPU想要读取一个不在其缓存行中的值
\(S\rightarrow I\)
- 流程:从共享变量\(x\),到变量\(x\)失效
- 流程:
- 收到一个Invalidate请求
- 发出一个Invalidate Acknowledge
- 触发时机:别的某个共享该变量\(x\)的CPU,想要对\(x\)进行修改
写优化
Store Buffer
为了优化写操作性能,在CPU和Cache之间引入了Store Buffer,写消息无需立即向其他CPU发送Invalidate消息,而是先写入Store Buffer中,然后立即返回执行其他操作,由Store Buffer异步执行发送广播消息,等到接收到其他CPU的响应后,再将数据从Store Buffer移到Cache中
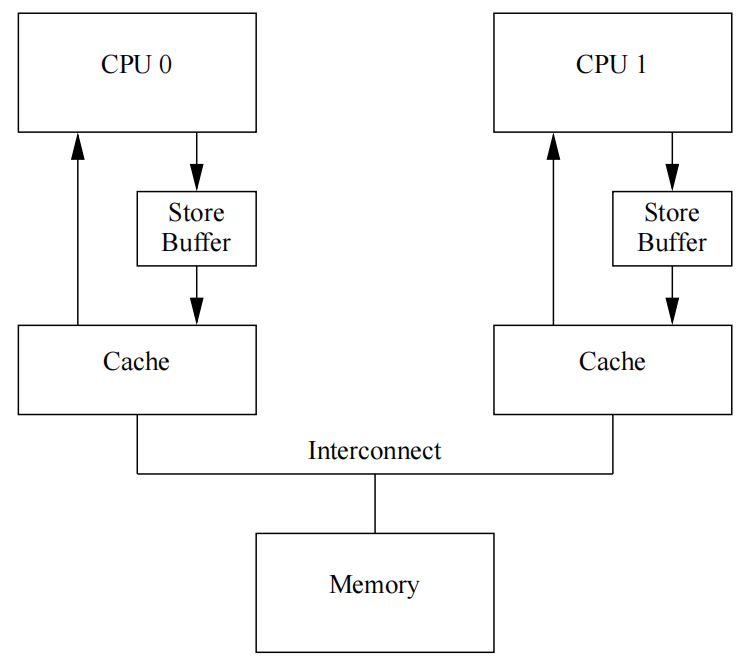
Store Forwarding
不过一个问题来了,假设当前CPU在Store Buffer中记录了写操作\(wop\)之后,继续之后的指令执行,并且执行了\(I=\{I_1,I_2,...,I_n\}\)这些指令,而其中某条指令\(I_k\in I\)依赖于\(wop\),那么就会出现程序员可见的bug,为了解决这个问题,我们允许CPU直接从Store Buffer里面找数据
Store Buffer造成的问题
Store Buffer中存储了对当前CPU的某个变量集合\(X=\{x_1,x_2,...,x_n\}\)尚未施加的修改,同时还有一个指令\(I\)是针对某个变量\(x_t\)的,满足\(x_t\notin X\),如果另外一个CPU请求这个变量\(x_t\)的值:
- 站在CPU的角度,\(I\)完全可以在Store Buffer没有清空的情况下执行,因为Store Buffer中根本不存在对\(x_t\)的影响
- 站在程序员的角度,有可能程序员希望看见\(I\)这条指令在\(x_i\in X\)被修改后执行,也就是Store Buffer的影响必须施加完毕后,再执行\(I\)
我们无法从硬件层面预测这种依赖关系,所以提供了Store Memory
Barrier,smp_wmb(),其作用是告诉处理器,在执行smp_wmb()时,应清空Store
Buffer
无Store Buffer
int a = 0, b = 0;
void foo() { // Cache中存在b = 0(E)
a = 1; // 远程无效化,收到Invalidate Ack后修改
b = 1; // 本地写,直接修改
}
void bar() { // Cache中存在a = 0(E)
while (b == 0) continue; // 远程读,读到b == 1后,本地对a的invalidate肯定生效了
assert(a == 1); // 远程读,读到a == 1
}有Store Buffer, 无内存屏障
int a = 0, b = 0;
void foo() { // Cache中存在b = 0(E)
a = 1; // 进入Store Buffer
b = 1; // 本地写,直接修改
}
void bar() { // Cache中存在a = 0(E)
while (b == 0) continue; // 远程读,读到b == 1,对a = 1的修改还在foo的Store Buffer中
assert(a == 1); // 本地读,本地对a的invalidate还没生效,assert fail
}有Store Buffer,有内存屏障
int a = 0, b = 0;
void foo() { // Cache中存在b = 0(E)
a = 1; // 进行Store Buffer
smp_wmb(); // 等待bar给出Invalidate Ack后,清空Store Buffer,a = 1(M)
b = 1; // 本地写,直接修改
}
void bar() { // Cache中存在a = 0(E)
while (b == 0) continue; // 远程读,读到b == 1,bar一定已经invalidate了a
assert(a == 1); // 远程读,读到a == 1
}Invalidate优化
Invalidate Acknowledge消息可能需要很长时间。其中一个原因是,它们必须确保相应的缓存行实际上无效,如果缓存繁忙,此Invalidate可能会延迟。例如,如果CPU集中加载和存储数据,且所有这些数据都位于缓存中。此外,如果大量Invalidate消息在短时间内到达,给定的CPU可能在处理它们用时过长
Invalidate Queue
CPU在收到Invalidate消息后,会存储在Invalidate Queue中,并立即响应Invalidate Acknowledge,之后Invalidate再异步执行缓存失效写操作
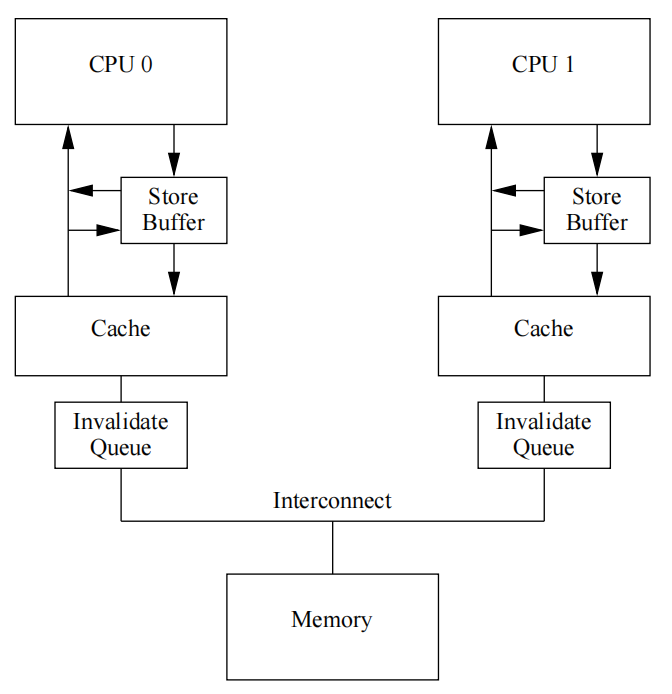
Invalidate Queue造成的问题
如果Invalidate Queue中存在某个失效操作,还没有来得及施加在Cache中的\(x\)上,CPU就开始使用\(x\)的旧值了,那么就造成了缓存不一致
我们提供了smp_rmb(),读屏障,其作用是告诉处理器,在执行smp_rmb(),应清空Invalidate
Queue